Wenn KI nachfragt: Dialogsysteme für eine sicherere Medikamenteneinnahme
Digitale Assistenzsysteme können bei der Medikamenteneinnahme helfen: Sie erinnern, erklären und geben Orientierung. Besonders nützlich werden sie, wenn sie nicht nur Antworten geben, sondern auch Rückfragen stellen.
Digitale Assistenzsysteme können bei der Medikamenteneinnahme helfen: Sie erinnern, erklären und geben Orientierung. Besonders nützlich werden sie, wenn sie nicht nur Antworten geben, sondern auch Rückfragen stellen.
Bei der mangelnden Adhärenz sind im Alltag die Ursachen nicht immer eindeutig. Hat jemand die Tablette schon genommen? Geht es um die Dosis am Morgen oder am Abend? Wurde die Medikamentenbox geöffnet, aber die Einnahme vielleicht unterbrochen? Genau in solchen Situationen soll unser Dialogsystem helfen und das Pflegepersonal richtig informieren.
 Test mit Proband*innen
Test mit Proband*innenWarum Rückfragen wichtig sind
Eine einfache Medikamentenerinnerung sagt: „Bitte nehmen Sie jetzt Ihre Tablette.“
Mit dem Dialogsystem wollen wir die genauen Gründe der Nichteinnahme erkennen:
- „Warum haben Sie Ihre Medikamente heute nicht genommen?“
- „Meinen Sie die Tablette von heute Morgen?“
- „Soll ich Sie später noch einmal erinnern?“
- „Möchten Sie, dass eine Betreuungsperson informiert wird?“
... und das Pflegepersonal über die Ergebnisse informieren.
Was das Dialogsystem können sollte
Das System erkennt, wenn eine Aussage unklar ist. Es fragt dann lieber einmal nach, statt vorschnell zu reagieren. Das ist gerade bei Medikamenten wichtig.
Beispiel:
Nutzer„Die habe ich schon genommen.“System„Meinen Sie die Tablette für heute Morgen?“
Oder:
Nutzer„Ich nehme die heute nicht.“System„Bitte ändern Sie Ihre Medikation nur nach Rücksprache mit Ihrer Ärztin, Ihrem Arzt oder Ihrer Pflegeperson. Was war der Grund warum Sie heute Ihre Medikamente nicht genommen haben?“
In unserem Fall gibt es selbst kein inhaltliches Feedback sondern verweist an das medizinische Fachpersonal.
Welche KI-Modelle kommen infrage?
Für solche Dialogsysteme gibt es verschiedene technische Ansätze. In der Regel macht es keinen Sinn eigene Modelle zu trainieren, da der Chat in der Lage sein muss vielseitig reagieren zu können was ein Vorteil von großen Large-Language-Modellen ist.
OpenAI: Realtime- und Audio-Modelle
OpenAI bietet Modelle für Speech-to-Speech-Anwendungen an. Dabei kann ein Modell Sprache hören, verarbeiten und direkt wieder gesprochen antworten. Das ist für Voice Agents interessant, weil Gespräche mit niedriger Latenz möglich werden.
Für die Medikamenten-Assistenzsystem is es nützlich, wenn die Interaktion möglichst natürlich laufen soll: zuhören, Kontext verstehen, Rückfragen stellen und gesprochen antworten.
Vorteile:
- sehr gutes Sprach- und Kontextverständniss
- geeignet für natürliche Audio-Dialoge
- schnelle Entwicklung und gute Entwicklerwerkzeuge
Zu beachten:
- Datenschutz und Datenminimierung schwierig
- externe Verarbeitung ist nicht für jede Anwendung ideal
- Kosten entstehen je nach Nutzung
In unseren Tests haben die aktuellen Live Audio Chatmodelle gpt-realtime-1.5 die besten Ergebnisse gezeigt.

Mistral Voxtral
Mistral bietet mit Voxtral Modelle für Audioverarbeitung an. Voxtral kann gesprochene Sprache verstehen und Fragen dazu beantworten. Zusätzlich gibt es Modelle für Transkription und Text-to-Speech. Besonders interessant ist, dass Teile der Voxtral-Familie als Open-Weight-Modelle verfügbar sind.
Das kann für Anwendungen spannend sein, bei denen mehr Kontrolle über Infrastruktur und Daten wichtig ist.
Vorteile:
- Gutes Audioverständnis und Transkription
- Open-Weight-Ansatz bei bestimmten Modellen
- interessant für eigene oder europäische Infrastruktur
Zu beachten:
- Integration und Betrieb sind schwierig und haben hohe Hardwareanforderungen
- Die Qualität ist schlechter als bei OpenAI Modellen

Google Gemma 4 mit Audio-Funktionen
Google hat bei Gemma 4 Audio-Fähigkeiten wie automatische Spracherkennung, Übersetzung und allgemeines Sprachverständnis und kann dabei gesprochene Inhalte in Text überführen und die Antwort generieren.
Für ein Audio-Chat-System ist Gemma ein guter Baustein, besonders weil Teile der Verarbeitung auch auf kleineren Computern lokal laufen.
Vorteile:
- Audioverständnis als Modellfähigkeit
- interessant für flexible Systemarchitekturen
- potenziell geeignet für lokale oder eigene Verarbeitung
Zu beachten:
- Sprachausgabe muss separat gelöst werden
- Relativ hohes Delay durch die separate Auswertung
Auch interessant: NVIDIA PersonaPlex
Besonders spannend ist NVIDIA PersonaPlex. PersonaPlex ist ein Speech-to-Speech-Modell für Echtzeitgespräche. Es basiert auf der Moshi-Architektur und ist als Full-Duplex-System ausgelegt. Das bedeutet: Das Modell kann zuhören und sprechen, während das Gespräch läuft: ähnlich wie in einer echten Unterhaltung.
Der Unterschied zu klassischen Systemen ist wichtig. PersonaPlex arbeitet nicht einfach nur als Kette aus Spracherkennung, Sprachmodell und Sprachausgabe. Es verarbeitet Audio kontinuierlich und erzeugt auch Audio als Antwort. Dadurch kann es besser mit Unterbrechungen, kurzen Bestätigungen und natürlichem Gesprächsrhythmus umgehen.
Ein weiterer Punkt ist die Steuerung der Rolle. PersonaPlex kann über Text-Prompts auf eine bestimmte Rolle eingestellt werden, zum Beispiel als Assistent, Kundenservice-Agent oder Lehrperson. Zusätzlich kann die Stimme über Audio-Beispiele beeinflusst werden. Für Anwendungen mit Avatar oder persönlicher Assistenz ist das interessant, weil Stimme und Verhalten konsistenter gestaltet werden können.
Basiert auf: Kyutai Moshi
Moshi ist ein Forschungs- und Open-Source-Projekt für Echtzeit-Sprachdialoge. Es wurde speziell dafür entwickelt, gesprochene Dialoge direkter zu verarbeiten. Das Ziel ist ein natürlicheres Gespräch mit weniger Verzögerung.
Vorteile:
- Fokus auf Echtzeit-Sprachdialog
- interessanter Open-Source-Ansatz
- zeigt, wohin Audio-Chat-Systeme technisch gehen
Zu beachten:
- Ist eher ein Forschungprojekt und wird nicht produktiv genutzt
- für sensible Anwendungen sind zusätzliche Tests und Sicherheitsmechanismen mit Hilfe anderer Modelle nötig
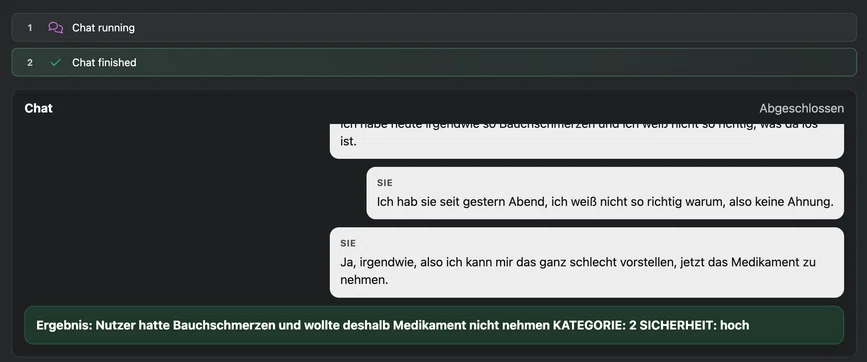 Feedback für das Pflegepersonal (Screenshot aus Debugansicht)
Feedback für das Pflegepersonal (Screenshot aus Debugansicht)Auswertung
Derzeit will der Chat nur herausfinden was die Ursache des Problems ist und geht nicht weiter auf den Patienten ein. Sobald der Chat weiß was der Grund ist bricht er das Gespräch ab und übermittelt den Grund an das Pflegepersonal.
